The PREMIS Data Dictionary is an international standard for metadata in order to ensure the preservation of digital objects and their long-term use. Developed by an international team of experts, PREMIS is implemented in digital conservation projects around the world, as well as a number of open-source and commercial systems for digital preservation tools. The Drafting Committee PREMIS coordinates revisions and the implementation of the standard, which consists of a Data Dictionary, a XML schema and documents.
PREMIS knows as core metadata associated with each object:
- Metadata that identify and define the'' OBJECT' and its position vis-à-vis other objects ('Structure of objects')
- Similarly for 'EVENT'
- Similarly for 'RIGHTS'
- Similarly for 'AGENTS'
PREMIS ads in version 3 a new type of entity called "INTELLECTUAL CONTENT." It is a set of objects that constitutes a single semantic topic for humans(As we shall see, in AXIS CSRM this entity is called "Semantic Entity" (AXIS CSRM in import / export and archive it comes to self-representations: the "Autonomous Semantic Entity" [ESA]. For the exchanges, the ASE’s are embedded in the Autonomous eXchange Entities (AXE))
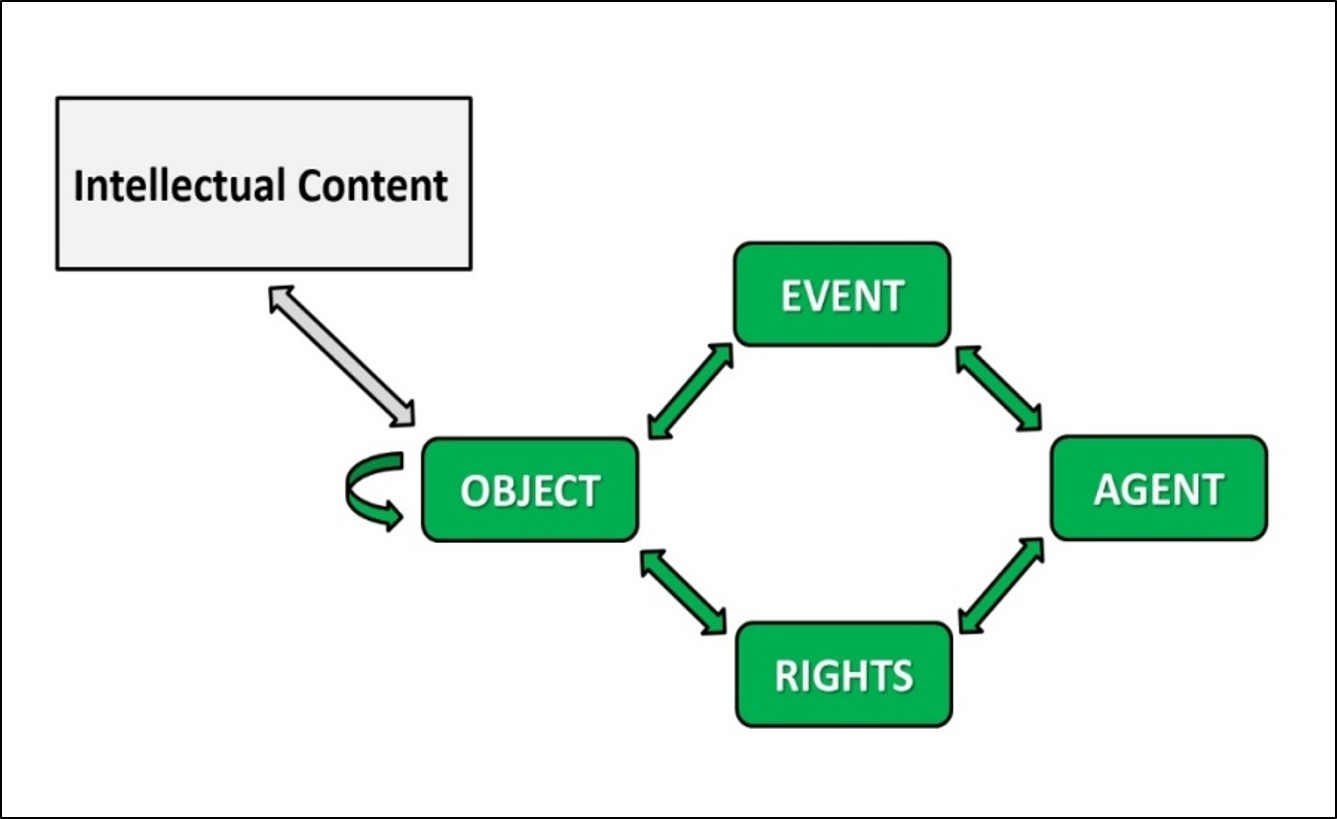
Figure 01 : Schéma des entités primaires de PREMIS (V 3)
Comments
PREMIS is very robust for its purpose. But as it does not rely on the methods and techniques of semantic representation, it does not make explicitly the difference between class and instance. In addition, it is very limited in the possibilities of structures expression.
Indeed, the real problematic is to manage the definition of the existence of objects and of the models of the objects: Modeling needs to answer the following four questions: where is the object? Where is the resource in the model? Which described the model of an object? Which is the subject of a model?